Confusion Matrix
| Prediction \ Ground-Truth | True | False |
| Positive | True Positive Correct Hit |
False Positive False Alarm (Type I Error) |
| Negative | False Negative Missing Result (Type II Error) |
True Negative Correct Rejection |
Type I Error: False Alram
좋은 중고차로 예측하고 구매했지만 실제로 좋지 않은 차인 경우
Type II Error: Missing Result
암환자를 건강하다고 판별하는 경우
1. Accuracy (정확도)
전체 예측 건수에서 정답을 맞힌 건수의 비율
모든 분류 건수 중에 정답을 맞춘 비율 (True, False 정확히 분류)
Accuracy = (TP + TN) / (TP + TN + FP + FN)
= (TP + TN) / (All Data)

Accuracy Paradox (정확도 역설):
희박한 확률의 결과를 예측할 때 (실제 데이터에 Negative 비율이 너무 높아서)
TP는 낮고 TN만 높아도 Accuracy 값은 높게 나온다. => Recall(재현율)로 평가
예) 폭설 예측, 결과가 TN만 나와도 Accuracy가 높다.
2. Recall (재현율)
object를 얼마나 잘 찾는가?
실제로 정답이 True인 것들(GT=True) 중 분류기가 TP로 예측한 비율
(True가 발생하는 확률이 적을 때 사용)
맞다고 분류해야 하는 건수 중에 제대로 분류한 비율
Recall = TP / (TP + FN) = TP / (All Ground-Truths)
단점: Accuracy와 반대로 TP만 맞추고 TN이 낮아도 Recall이 높게 나옴
3. Precision (정밀도)
찾은 object가 정확한가?
True로 예측(Positive)한 건수(TP + FP) 중 실제로 TP인 비율
분류기가 맞다고 예측한 건수 중에 실제로 맞은 건수 비율
Precision = TP / (TP + FP) = TP / (All Detections)
단점: Recall의 장점
Reference: https://darkpgmr.tistory.com/162
precision, recall의 이해
자신이 어떤 기술을 개발하였다. 예를 들어 이미지에서 사람을 자동으로 찾아주는 영상 인식 기술이라고 하자. 이 때, 사람들에게 "이 기술의 검출율은 99.99%입니다"라고 말하면 사람들은 "오우..
darkpgmr.tistory.com
| Accuracy = (TP + TN) / (TP + TN + FP + FN) | Precision = TP / (TP + FP) |
| 정확도 | 정밀도 |
| 결과가 참값(TP + TN)에 얼마나 가까운지 | 얼마나 일관된 값을 출력하는지 |
| 시스템의 bias | 반복 정밀도 |
예) 몸무게 50kg인 사람의 몸무게 측정, 60, 60.12, 59.99, ... 와 같이 60kg 근처 값으로 나오면
이 저울의 accuracy는 매우 낮지만 precision은 높다.
4. F1-score (조화평균)
F1-score = 2 x (Precision x Recall) / (Precision + Recall)
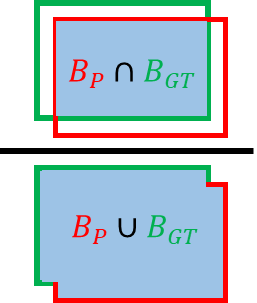
5. IoU (Intersection over Union)
IoU = TP / (TP + FP + FN)
= Area(GT ∩ Prediction) / Area(GT ∪ Prediction)
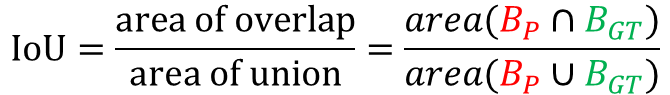
보통 0.5 값을 기준으로 함
6. AP(Average Precision)
PR곡선(Precision, Recall)을 그렸을 때, 근사되는 넓이
PR Curve : Confidence 레벨에 대한 threshold 값의 변환에 대해 물체 검출기의 성능 평가
Reference: https://bskyvision.com/465
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해
물체 검출(object detection) 알고리즘의 성능은 precision-recall 곡선과 average precision(AP)로 평가하는 것이 대세다. 이에 대해서 이해하려고 한참을 구글링했지만 초보자가 이해하기에 적당한 문서는 찾
bskyvision.com
7. mAP(mean Average Precision)
class가 여러개인 경우 평균 AP
Reference: https://github.com/Cartucho/mAP
GitHub - Cartucho/mAP: mean Average Precision - This code evaluates the performance of your neural net for object recognition.
mean Average Precision - This code evaluates the performance of your neural net for object recognition. - GitHub - Cartucho/mAP: mean Average Precision - This code evaluates the performance of your...
github.com
'ML' 카테고리의 다른 글
| COCO Dataset (0) | 2023.08.16 |
|---|---|
| Pascal VOC(Visual Object Classes) Challenges (0) | 2023.08.15 |
| 윈도우 버전 YOLO v3 설치 (0) | 2021.08.16 |