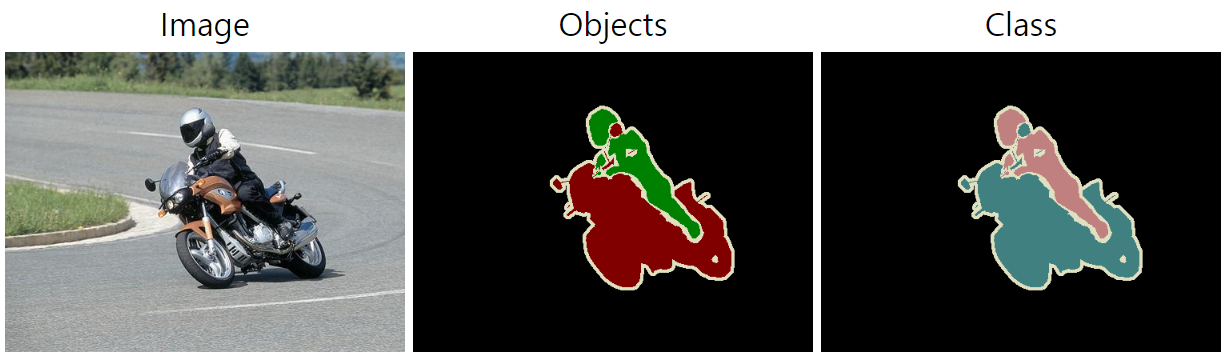
COCO - Common Objects in Context
cocodataset.org
COCO(Common Object in Context)
is a large-scale object dtection, segmentation, and captioning dataset.
features:
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- 330K images (> 200K labeled)
- 1.5 million object instances
- 80 object categories
- 91 stuff categories
- 5 captions per image
- 250,000 people with keypoints
Data format
All annotations share the same basic data structure below:
{ "info": info, "images": [image], "annotations": [annotation], "licenses": [license], } info: { "year": int, "version": str, "description": str, "contributor": str, "url": str, "date_created": datetime, } image: { "id": int, "width": int, "height": int, "file_name": str, "license": int, "flickr_url": str, "coco_url": str, "date_captured": datetime, } license: { "id": int, "name": str, "url": str, }
1. Object Detection

Each object instance annotation contains a series of fields,
including the category id and segmentation mask of the object.
annotation: { "id": int, "image_id": int, "category_id": int, "segmentation": RLE or [polygon], "area": float, "bbox": [x,y,width,height], "iscrowd": 0 or 1, } categories: [ { "id": int, "name": str, "supercategory": str, } ]
- iscrowd: large groups of objects (e.g. a crowd of people)
- 0 = single object, polygons used
- 1 = collection of objects, RLE used
- segmentation
- RLE(Run Length Encoding)
- counts: [ ... ]
- size: [ width, height ]
- [ polygon ]
- polygon: [ x1, y1, x2, y2, ... ]
- RLE(Run Length Encoding)
- bbox: enclosing bounding box,
2. Keypoint Detection
annotation: { : : object detection annotations : "keypoints": [x1, y1, v1, ...], "num_keypoints": int, : , } categories: [ { : : object detection annotations : "keypoints": [str], "skeleton": [edge] } ]
- annotation
- keypoints: a length 3k array where k is the total number of keypoints defined for the category
- each keypoint has a 0-indexed location x, y and a visibility flag v
- v=0: not labed (in which case x=y=0)
- v=1: labeld but not visible
- v=2: labeld and visible
- num_keypoint: the number of labeled keypoints (v > 0) for a given object
(many objects, e.g. crowds and small objects, will have num_keypoints=0).
- keypoints: a length 3k array where k is the total number of keypoints defined for the category
- categories
- keypoints: a length k array of keypoint names
- skeleton: defines connectivity via a list of keypoint edge pairs
- edge: [ index1, index2 ]
"categories": [ { "supercategory": "person", "id": 1, "name": "person", "keypoints": [ "nose", "left_eye", "right_eye", "left_ear", "right_ear", "left_shoulder", "right_shoulder", "left_elbow", "right_elbow", "left_wrist", "right_wrist", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle", "right_ankle" ], "skeleton": [ [16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12], [7, 13], [6, 7], [6, 8], [7, 9], [8, 10], [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7] ] } ]
3. Stuff Segmentation

The stuff annotation format is idential and fully compatible to the object detection format above
(except iscrowd is unnecessary and set to 0 by default).
...
4. Panoptic Segmentation

For the panotic task, each annotation struct is a per-image annotation rather than a per-object annotation.
Each per-image annotation has two parts:
(1) a PNG that stores the class-agnostic image segmentation and
(2) a JSON struct that stores the semantic information for each image segmentation.
...
- annotation.image_id == image.id
- For each annotation, per-pixel segment ids are stored as a single PNG at annotation.file_name.
- For each annotation, per-segment info is stored in annotation.segments_info.
segment_info.id stores the unique id of the segment and is used to retrieve the corresponding mask from the PNG.- category_id gives the semantic category
- iscrowd indicates the segment encompasses a group of objects (relevant for thing categories only).
- The bbox and area fields provide additional info about the segment.
- The COCO panoptic task has the same thing categories as the detection task,
whereas the stuff categories differ from those in the stuff task.
Finally, each category struct has two additional fields:- isthing: distinguishes stuff and thing categories
- color: is useful for consistent visualization
annotation: { "image_id": int, "file_name": str, "segments_info": [segment_info], } segment_info: { "id": int, "category_id": int, "area": int, "bbox": [x, y, width, height], "iscrowd": 0 or 1, } categories: [ { "id": int, "name": str, "supercategory": str, "isthing": 0 or 1, "color": [R,G,B], } ]
5. Image Captioning

These annotations are used to store image captions.
Each caption describes the specified image and each image has at least 5 captions (some images have more).
annotation: { "id": int, "image_id": int, "caption": str, }
6. DensePose

Each annotation contains a series of fields, including category id, bounding box, body part masks and parametrization data for selected points.
DensePose annotations are stored in dp_* fields:
Annotated masks:
- dp_masks: RLE encoded dense masks.
- All part masks are of size 256x256.
- They correspond to 14 semantically meaningful parts of the body:
Torso, Left/Right Hand, Left/Right Foot, Upper Leg Left/Right, Lower Leg Left/Right, Upper Arm Left/Right, Lower Arm Left/Right, Head;
Annotated points:
- dp_x, dp_y: spatial coordinates of collected points on the image.
- The coordinates are scaled such that the boudning box size is 256x256.
- dp_I: The patch index that indicates which of the 24 surface patches the point is on.
- Patches correspond to the body parts described above.
Some body parts are split into 2 patches:- Torso
- Right Hand
- Left Hand
- Left Foot
- Right Foot
- Upper Leg Right
- Upper Leg Left
- Lower Leg Right
- Lower Leg Left
- Upper Arm Left
- Upper Arm Right
- Lower Arm Left
- Lower Arm Right
- Head
- Patches correspond to the body parts described above.
- dp_U, dp_V: Coordinates in the UV space.
Each surface patch has a separate 2D parameterization.
annotation: { "id": int, "image_id": int, "category_id": int, "is_crowd": 0 or 1, "area": int, "bbox": [x, y, width, height], "dp_I": [float], "dp_U": [float], "dp_V": [float], "dp_x": [float], "dp_y": [float], "dp_masks": [RLE], }
'ML' 카테고리의 다른 글
| Pascal VOC(Visual Object Classes) Challenges (0) | 2023.08.15 |
|---|---|
| 분류 모델의 성능평가지표 Accuracy, Recall, Precision, F1-score (0) | 2022.12.19 |
| 윈도우 버전 YOLO v3 설치 (0) | 2021.08.16 |